Open Source
Terracotta Server Array Architecture
A Terracotta Server Array (TSA) can vary from a basic two-node tandem to a multi-node array. The Terracotta cluster can be configured into a number of different setups to serve both deployment stage and production needs. This page shows you how to add cluster reliability, availability, and scalability.
Terracotta Cluster in Development
Persistence: No | Failover: No | Scale: No
In a development environment, persisting shared data is often unnecessary and even inconvenient. Running a single-server Terracotta cluster without persistence is a good solution for creating an efficient development environment.
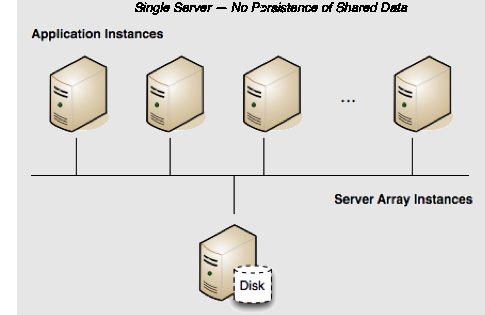
By default, a Terracotta server has Fast Restartability disabled, which means it will not persist data after a restart. Its configuration could look like the following:
<?xml version="1.0" encoding="UTF-8" ?>
<tc:tc-config xmlns:tc="http://www.terracotta.org/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.terracotta.org/schema/terracotta-8.xsd">
<servers>
<server name="Server1">
<data>/opt/terracotta/server1-data</data>
<tsa-port>9510</tsa-port>
<offheap>
<enabled>true</enabled>
<maxDataSize>2g</maxDataSize>
</offheap>
</server>
</servers>
...
</tc:tc-config>
If this server goes down, the application state (all clustered data) in the shared memory is lost. In addition, when the server is up again, all clients must be restarted to rejoin the cluster. Note that servers are required to run with off-heap, and that shared data is also lost.
Terracotta Cluster with Reliability
Persistence: Yes | Failover: No | Scale: No
The configuration above may be advantageous in development, but if shared in-memory data must be persisted, the server should be configured to use its local disk. Terracotta servers achieve data persistence with the Fast Restart feature.
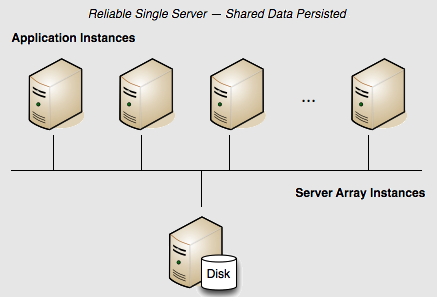
Fast Restartability
The Fast Restart feature provides enterprise-ready crash resilience by keeping a fully consistent, real-time record of your in-memory data. After any kind of shutdown — planned or unplanned — the next time your application starts up, all of your BigMemory Max data is still available and very quickly accessible.
The Fast Restart feature persists the real-time record of the in-memory data in a Fast Restart store on the server's local disk. After any restart, the data that was last in memory (both heap and off-heap stores) automatically loads from the Fast Restart store back into memory. In addition, previously connected clients are allowed to rejoin the cluster within a window set by the <client-reconnect-window> element.
To configure the Terracotta server for Fast Restartability, add and enable the <restartable> and the <offheap> elements in the tc-config.xml.
<?xml version="1.0" encoding="UTF-8" ?>
<tc:tc-config xmlns:tc="http://www.terracotta.org/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.terracotta.org/schema/terracotta-8.xsd">
<servers>
<server name="Server1">
<data>/opt/terracotta/server1-data</data>
<tsa-port>9510</tsa-port>
<offheap>
<enabled>true</enabled>
<maxDataSize>2g</maxDataSize>
</offheap>
</server>
<!-- Fast Restartability must be added explicitly. -->
<restartable enabled="true"/>
<!-- By default the window is 120 seconds. -->
<client-reconnect-window>120</client-reconnect-window>
</servers>
...
</tc:tc-config>
Terracotta server memory allocation
Fast Restartability requires that <offheap> be enabled with a minimum setting for maxDataSize of 512MB. Refer to the following table for store size guidelines for servers in the TSA.
| When Off-heap is set between | Configure at least this much Heap |
|---|---|
| 4 - 10 GB | 1 GB (Note: The default heap size is 2 GB.) |
| 10 - 100 GB | 2 GB |
| 100 GB - 1 TB + | 3 GB + |
| (Off-heap is configured in the tc-config.xml) | (Heap is configured using the -Xmx Java option) |
Disk usage
Fast Restartability requires a unique and explicitly specified path. The default path is the Terracotta server's home directory. You can customize the path using the <data> element in the server's tc-config.xml configuration file.
The Terracotta Server Array can be configured to be restartable in addition to including searchable caches, but both of these features require disk storage. When both are enabled, be sure that enough disk space is available. Depending upon the number of searchable attributes, the amount of disk storage required might be 3 times the amount of in-memory data.
It is highly recommended to store the search index (<index>) and the Fast Restart data (<data>) on separate disks.
Client Reconnect Window
The <client-reconnect-window> does not have to be explicitly set if the default value is acceptable. However, in a single-server cluster, <client-reconnect-window> is in effect only if restartable mode is enabled.
Terracotta Server Array with High Availability
Persistence: Yes | Failover: Yes | Scale: No
The example above presents a reliable but not highly available cluster. If the server fails, the cluster fails. There is no redundancy to provide failover. Adding a mirror server adds availability because the mirror serves as a "hot standby" ready to take over for the active server in case of a failure.
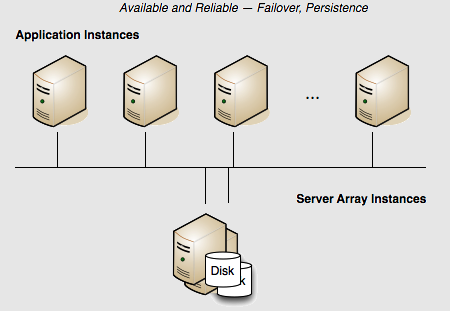
In this array, if the active Terracotta server instance fails, then the mirror instantly takes over and the cluster continues functioning. No data is lost.
The following Terracotta configuration file demonstrates how to configure this two-server array:
<?xml version="1.0" encoding="UTF-8" ?>
<tc:tc-config xmlns:tc="http://www.terracotta.org/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.terracotta.org/schema/terracotta-8.xsd">
<servers>
<server name="Server1">
<data>/opt/terracotta/server1-data</data>
<tsa-port>9510</tsa-port>
<tsa-group-port>9530</tsa-group-port>
<offheap>
<enabled>true</enabled>
<maxDataSize>2g</maxDataSize>
</offheap>
</server>
<server name="Server2">
<data>/opt/terracotta/server2-data</data>
<tsa-port>9510</tsa-port>
<tsa-group-port>9530</tsa-group-port>
<offheap>
<enabled>true</enabled>
<maxDataSize>2g</maxDataSize>
</offheap>
</server>
<restartable enabled="true"/>
<client-reconnect-window>120</client-reconnect-window>
</servers>
...
</tc:tc-config>
You can add more mirror servers to this configuration by adding more <server> sections. However, a performance overhead may become evident when adding more mirror servers due to the load placed on the active server by having to synchronize with each mirror.
Note: Terracotta server instances must not share data directories. Each server's <data> element should point to a different and preferably local data directory.
Starting the Servers
How server instances behave at startup depends on when in the life of the cluster they are started.
In a single-server configuration, when the server is started it performs a startup routine and then is ready to run the cluster (ACTIVE status). If multiple server instances are started at the same time, one is elected the active server (ACTIVE-COORDINATOR status) while the others serve as mirrors (PASSIVE-STANDBY status). The election is recorded in the servers' logs.
If a server instance is started while an active server instance is already running, it syncs up state from the active server instance before becoming a mirror. The active and mirror servers must always be synchronized, allowing the mirror server to mirror the state of the active. The mirror server goes through the following states:
- PASSIVE-UNINITIALIZED – The mirror is beginning its startup sequence and is not ready to perform failover should the active fail or be shut down. The server's status light in the Terracotta Management Console (TMC) switches from red to orange.
- INITIALIZING – The mirror is synchronizing state with the active and is not ready to perform failover should the active fail or be shut down. The server's status light in the TMC is orange.
- PASSIVE-STANDBY – The mirror is synchronized and is ready to perform failover should the active server fail or be shut down. The server's status light in the TMC switches from orange to cyan.
The active server instance carries the load of sending state to the mirror during the synchronization process. The time taken to synchronize is dependent on the amount of clustered data and on the current load on the cluster. The active server instance and mirrors should be run on similarly configured machines for better throughput, and should be started together to avoid unnecessary sync ups.
The sequence in which servers startup does not affect data. Even if a former mirror server is initialized before the former active server, the mirror server's data is not erased. In the event that a mirror server went offline while the active server was still up, then when the mirror server returns, it remembers that it was in the mirror role. Even if the active server is offline at that point, the mirror server does not try to become the active. It waits until the active server returns, and clients are blocked from updating their data. When the active returns, it will restart the mirror. The mirror's data objects and indices are then moved to the dirty-objectdb-backup directory, and the active syncs its data with the mirror.
Failover
If the active server instance fails and two or more mirror server instances are available, an election determines the new active. Successful failover to a new active takes place only if at least one mirror server is fully synchronized with the failed active server; successful client failover (migration to the new active) can happen only if the server failover is successful. Shutting down the active server before a fully-synchronized mirror is available can result in a cluster-wide failure.
If the maxDataSize on the mirror server is smaller than on the active server, then the mirror server will fail to start and the user will be alerted that the configuration is invalid. If there are multiple mirrors with differing amounts of off-heap configured, then the passive with the smallest maxDataSize (that is still greater than or equal to the active's maxDataSize) will be elected to be the new active.
| A mirror can be hot-swapped if the replacement matches the original mirror’s <server> block in the Terracotta configuration. For example, the new mirror should use the same host name or IP address configured for the original mirror. For information about swapping in a mirror with a different configuration, refer to Changing Cluster Topology in a Live Cluster. |
Terracotta server instances acting as mirrors can run either in restartable mode or non-persistent mode. If a server instance running in restartable mode goes down, and a mirror takes over, the crashed server's data directory is cleared before it is restarted and allowed to rejoin the cluster. Removing the data is necessary because the cluster state could have changed since the crash. During startup, the restarted server's new state is synchronized from the new active server instance.
If both servers are down, and clustered data is persisted, the last server to be active will automatically be started first to avoid errors and data loss.
In setups where data is not persisted, meaning that restartable mode is not enabled, then no data is saved and either server can be started first.
A Safe Failover Procedure
To safely migrate clients to a mirror server without stopping the cluster, follow these steps:
- If it is not already running, start the mirror server using the start-tc-server script. The mirror server must already be configured in the Terracotta configuration file.
- Ensure that the mirror server is ready for failover (PASSIVE-STANDBY status). In the TMC, the status light will be cyan.
Shut down the active server using the stop-tc-server script.
NOTE: If the script detects that the mirror server in STANDBY state isn't reachable, it issues a warning and fails to shut down the active server. If failover is not a concern, you can override this behavior with the
--forceflag.Clients will connect to the new active server.
Restart any clients that fail to reconnect to the new active server within the configured reconnection window.
The previously active server can now rejoin the cluster as a mirror server. If restartable mode had been enabled, its data is first removed and then the current data is read in from the now active server.
A Safe Cluster Shutdown Procedure
A safe cluster shutdown should follow these steps:
- Shut down the mirror servers using the stop-tc-server script.
- Shut down the clients. The Terracotta client will shut down when you shut down your application.
- Shut down the active server using the stop-tc-server script.
To restart the cluster, first start the server that was last active. If clustered data is not persisted, any of the servers could be started first as no data conflicts can take place.
Split Brain Scenario
In a Terracotta cluster, "split brain" refers to a scenario where two servers assume the role of active server (ACTIVE-COORDINATOR status). This can occur during a network problem that disconnects the active and mirror servers, causing the mirror to both become an active server and open a reconnection window for clients (<client-reconnect-window>).
If the connection between the two servers is never restored, then two independent clusters are in operation. This is not a split-brain situation. However, if the connection is restored, one of the following scenarios results:
- No clients connect to the new active server – The original active server "zaps" the new active server, causing it to restart, wipe its database, and synchronize again as a mirror.
- A minority of clients connect to the new active server – The original active server starts a reconnect timeout for the clients that it loses, while zapping the new active server. The new active restarts, wipes its database, and synchronizes again as a mirror. Clients that defected to the new active attempt to reconnect to the original active, but if they do not succeed within the parameters set by that server, they must be restarted.
- A majority of clients connects to the new active server – The new active server "zaps" the original active server. The original active restarts, wipes its database, and synchronizes again as a mirror. Clients that do not connect to the new active within its configured reconnection window must be restarted.
- An equal number of clients connect to the new active server – In this unlikely event, exactly one half of the original active server's clients connect to the new active server. The servers must now attempt to determine which of them holds the latest transactions (or has the freshest data). The winner zaps the loser, and clients behave as noted above, depending on which server remains active. Manual shutdown of one of the servers may become necessary if a timely resolution does not occur.
The Terracotta cluster can solve almost all split-brain occurrences without loss or corruption of shared data. However, it is highly recommended that you confirm the integrity of shared data after such an occurrence.
Scaling the Terracotta Server Array
Persistence: Yes | Failover: Yes | Scale: Yes
For capacity requirements that exceed the capabilities of a two-server active-mirror setup, expand the Terracotta cluster using a mirror-groups configuration. Using mirror groups with multiple coordinated active Terracotta server instances adds scalability to the Terracotta Server Array.
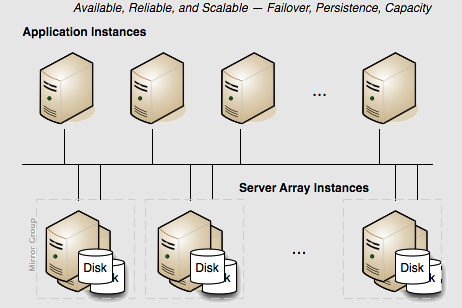
Mirror groups are specified in the <servers> section of the Terracotta configuration file. Mirror groups work by assigning group memberships to Terracotta server instances. The following snippet from a Terracotta configuration file shows a mirror-group configuration with four servers:
...
<servers>
<mirror-group election-time="10" group-name="groupA">
<server name="server1">
...
</server>
<server name="server2">
...
</server>
</mirror-group>
<mirror-group election-time="15" group-name="groupB">
<server name="server3">
...
</server>
<server name="server4">
...
</server>
</mirror-group>
<restartable enabled="true"/>
</servers>
...
In this example, the cluster is configured to have two active servers, each with its own mirror. If server1 is elected active in groupA, server2 becomes its mirror. If server3 is elected active in groupB, server4 becomes its mirror. server1 and server3 automatically coordinate their work managing Terracotta clients and shared data across the cluster.
In a Terracotta cluster designed for multiple active Terracotta server instances, the server instances in each mirror group participate in an election to choose the active. Once every mirror group has elected an active server instance, all the active server instances in the cluster begin cooperatively managing the cluster. The rest of the server instances become mirrors for the active server instance in their mirror group. If the active in a mirror group fails, a new election takes place to determine that mirror group's new active. Clients continue work without regard to the failure.
| Under <servers>, you may use either <server> or <mirror-group> configurations, but not both. All <server> configurations directly under <servers> work together as one mirror group, with one active server and the rest mirrors. To create more than one stripe, use <mirror-group> configurations directly under <servers>. The mirror group configurations then include one or more <server> configurations. |
In a Terracotta cluster with mirror groups, each group, or "stripe," behaves in a similar way to an active-mirror setup (see Terracotta Server Array with High Availability). For example, when a server instance is started in a stripe while an active server instance is present, it synchronizes state from the active server instance before becoming a mirror. A mirror cannot become an active server instance during a failure until it is fully synchronized. If an active server instance running in restartable mode goes down, and a mirror takes over, the data directory is cleared before bringing back the crashed server.
Election Time
The <mirror-group> configuration allows you to declare the election time window. An active server is elected from the servers that cast a vote within this window. The value is specified in seconds and the default is 5 seconds. Network latency and the work load of the servers should be taken into consideration when choosing an appropriate window.
In the above example, the servers in groupA can take up to 10 seconds to elect an active server, and the servers in groupB can take up to 15 seconds.
Stripe and Cluster Failure
If the active server in a mirror group fails or is taken down, the cluster stops until a mirror takes over and becomes active (ACTIVE-COORDINATOR status).
However, the cluster cannot survive the loss of an entire stripe. If an entire stripe fails and no server in the failed mirror-group becomes active within the allowed window (based on the election-time setting), the entire cluster must be restarted.