Commercial Products
Open Source
A Brief on Terracotta Health Monitoring
Terracotta Heath Monitoring module takes care to figure the state of connectedness of all the Terracotta entities in a clustered deployment. Health Monitoring automatically detects various failure scenarios that may occur in a cluster and takes corrective actions to ensure that the cluster participants follow the necessary failover protocols to ensure the cluster is highly available at all points of time. This works independently of the application threads and therefore adds no performance overhead to the application.
Variables and Usage
The Health Monitoring module exposes a few tunable parameters through the Terracotta configuration file. These parameters give the necessary flexibility to the deployment scheme for setting fine-grained tolerance values for various perceived failure scenarios.
The Health Monitoring goes on in the following directions:
- Between Terracotta Clients and Terracotta Active Server (L1 -> L2)
- Between Terracotta Active Server and Terracotta Passive Server (L2 -> L2)
- Between Terracotta Active Server and Terracotta Clients (L2 -> L1)
Following are the parameters:
| Variable Name | Description |
|---|---|
| l2.healthcheck.l1.ping.enabled l2.healthcheck.l2.ping.enabled l1.healthcheck.l2.ping.enabled | Enables (True) or disables (False) ping probes (tests). Ping probes are high-level attempts to gauge the ability of a remote node to respond to requests and is useful for determining if temporary inactivity or problems are responsible for the node's silence. Ping probes may fail due to long GC cycles on the remote node. |
| l2.healthcheck.l1.ping.interval l2.healthcheck.l2.ping.interval l1.healthcheck.l2.ping.interval | If no response is received to a ping probe, the time (in milliseconds) that HealthChecker waits between retries. |
|
l2.healthcheck.l1.ping.probes l2.healthcheck.l2.ping.probes l1.healthcheck.l2.ping.probes |
If no response is received to a ping probe, the maximum number (integer) of retries HealthChecker can attempt. |
|
l2.healthcheck.l1.socketConnect l2.healthcheck.l2.socketConnect l1.healthcheck.l2.socketConnect |
Enables (True) or disables (False) socket-connection tests. This is a low-level connection that determines if the remote node is reachable and can access the network. Socket connections are not affected by GC cycles. |
|
l2.healthcheck.l1.socketConnectTimeout l2.healthcheck.l2.socketConnectTimeout l1.healthcheck.l2.socketConnectTimeout |
A multiplier (integer) to determine the maximum amount of time that a remote node has to respond before HealthChecker concludes that the node is dead (regardless of previous successful socket connections). The time is determined by multiplying the value in ping.interval by this value. |
|
l2.healthcheck.l1.socketConnectCount l2.healthcheck.l2.socketConnectCount l1.healthcheck.l2.socketConnectCount |
The maximum number (integer) of successful socket connections that can be made without a successful ping probe. If this limit is exceeded, HealthChecker concludes that the target node is dead. |
| l2.nha.tcgroupcomm.reconnect.enabled | Enables a server instance to attempt reconnection with its peer server instance after a disconnection is detected. Default: false |
| l2.nha.tcgroupcomm.reconnect.timeout | Enabled if l2.nha.tcgroupcomm.reconnect.enabled is set to true. Specifies the timeout (in milliseconds) for reconnection. Default: 2000. This parameter can be tuned to handle longer network disruptions |
| l2.l1reconnect.enabled | Enables a client to rejoin a cluster after a disconnection is detected. This property controls a server instance's reaction to such an attempt. It is set on the server instance and is passed to clients by the server instance. A client cannot override the server instance's setting. If a mismatch exists between the client setting and a server instance's setting, and the client attempts to rejoin the cluster, the client emits a mismatch error and exits. Default: true |
| l2.l1reconnect.timeout.millis | Enabled if l2.l1reconnect.enabled is set to true. Specifies the timeout (in milliseconds) for reconnection. This property controls a server instance's timeout during such an attempt. It is set on the server instance and is passed to clients by the server instance. A client cannot override the server instance's setting. Default: 2000. This parameter can be tuned to handle longer network disruptions. |
A Word about Reconnect Properties
The Reconnect properties lend another useful characteristics to the clustered deployment in case of small outages. If any Terracotta clustered entity happens to suffer a sudden network socket disruption, all the other entities that are monitoring its health get an EOF at their sockets instantly. In a normal case, when reconnect properties are not used, the entity which crashed is immediately quarantined from the cluster.
With reconnect properties enabled, all other cluster participants open a small window of opportunity for the crashed component to come back up alive and join the cluster. So this prohibits the Health Monitoring from severing the connection before the reconnection window closes on itself.
This works autonomously from the Health Monitoring process. These two processes work mutually exclusively. So, if Health Monitoring declares any cluster participant entity as dead, reconnect properties do not get applied to it (as in once declared dead, no reconnect time window will be opened). On the other hand, the Health Monitoring does not kick in once the reconnect window is over.
Tolerance Formula and Flowchart
The final tolerance formula is denoted as:
Max Time = (ping.idletime) + socketConnectCount * [(ping.interval * ping.probes)
+ (socketConnectTimeout * ping.interval)]
OR
Max Time = reconnect.timeout.millis (in certain cases only)
The Health Monitoring module determines the other cluster entities' health based on the following flowchart process:
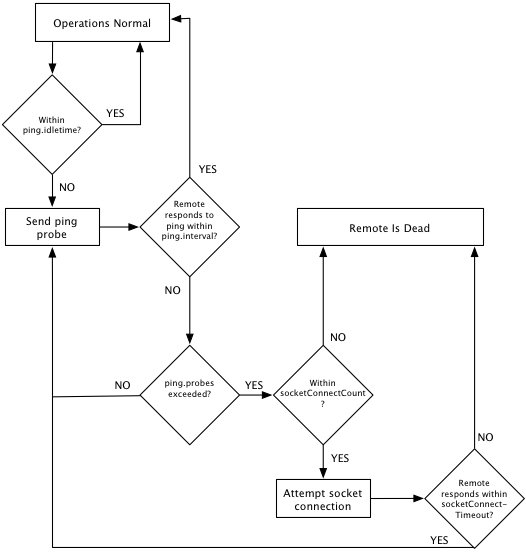
Depending on the deployment network's reliability and the degree of tolerance that is required, these parameters are tuned to give the desired result.
For more details, review the HealthChecker documentation.
Assumptions
- All results in this document are taken considering that if clustered peer is alive, then it is able to accept connection with in ping.interval timeframe
- All numeric values conform to the default values inside the tc-config.xml