Open Source
Terracotta Server Array Operations
Automatic Resource Management
Terracotta Server Array resource management involves self-monitoring and polling to determine the real-time size of the data set and assess the amount of memory remaining according to user-configured limitations. In-memory data can be managed from three directions:
Time – TTI/TTL settings can be configured to expire entries that will then be evicted by the new TSA eviction implementation. You can also configure caches so that their entries are eternal, or you can pin entries or caches so that they are never evicted.
Size – The total amount of BigMemory managed by the TSA can be configured using the
maxDataSizechild element in the tc-config.xml file.Count – The total number of entries per cache can be configured using the
maxEntriesInCacheattribute in the ehcache.xml file.
Eviction
All data is kept in memory, and the TSA runs evictions in the background to keep the data set within its limitations. Eviction of entries from the data set reduces the amount of data before the memory becomes full. The criteria for an entry to be eligible for eviction are:
- It is not on a Terracotta client (L1).
- It is not pinned to a Terracotta server.
- It is held in a cache backed by a System of Record (SOR).
| BigMemory's in-memory data is treated as a "store" when BigMemory owns the data, and as a "cache" when the data also resides in a System of Record (SOR). Generally, data that is created by BigMemory and run-time data created by your application are examples of data that is treated as a store. The TSA does not evict data stores because they are the only or primary records. The TSA can evict cached data because that data is backed up in an SOR. (Distinctions in data structures are handled automatically, but you can also use the Terracotta Toolkit API to configure customized data structures.) |
Eviction is done by the following evictors, which work together in the background:
The periodic evictor is activated on an as-needed basis. It removes expired entries based on TTI/TTL settings. The Server Expiration Rate graph in the TMC shows the activity of the periodic evictor.
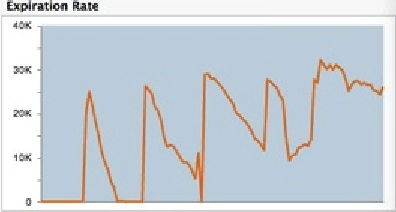
The resource-based evictor is activated by the periodic TTI/TTL eviction scheduler, as well as by resource monitoring events. This evictor continuously polls heap and off-heap stores to check current resource usage. At approximately 10% usage of the
maxDataSize(configured in the tc-config.xml file), it starts looking for TTI/TTL-expired elements to evict. At approximately 90% usage, it evicts live as well as expired elements. If a monitored resource goes over its critical threshold, this evictor will work continually until the monitored resource falls below the critical threshold.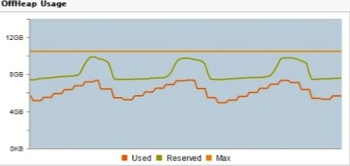
This evictor actually monitors two thresholds, used space and reserved space. Resource eviction is triggered if either the reserved or used is above its threshold. Once resource eviction has started, both used and reserve must fall below their respective thresholds before resource eviction ends.
The Offheap Usage graph in the TMC provides the following information:
- Off-heap Max is the configured maxDataSize
- Off-heap Reserved represents usage of the space that is reserved for the system
- Off-heap Used represents the amount BigMemory that is in use
The capacity-based evictor is activated when a cache goes over its maximum count (as configured with
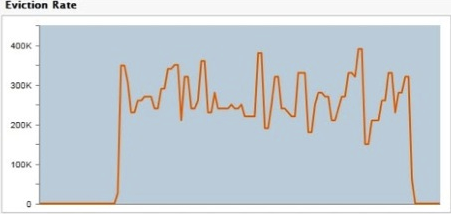
maxEntriesInCache), plus an overshoot count, and it attempts to bring the size of the cache to the max capacity. ThemaxEntriesInCacheattribute must be present in the Ehcache configuration (do not includemaxEntriesInCachein your configuration if you do not want the capacity evictor to run). IfmaxEntriesInCacheis not set, it gets the default value 0, which means that the cache is unbounded and will not undergo capacity eviction (but periodic and resource evictions are still allowed).The Server Eviction Rate graph in the TMC shows the activity of the resource and capacity evictors.
Customizing the Eviction Strategy
Based upon the three types of evictors, there are three strategies that you can employ for controlling the size of the TSA's data set:
Set the Time To Idle (TTI) or Time to Live (TTL) options for any entry in your data set. After the time has expired, the periodic evictor will clear the entry.
Set the
maxDataSizeelement to control how much BigMemory should be used before the resource-based evictor is activated.Set the
maxEntriesInCacheattribute to control when the capacity-based evictor is activated.
Near-Memory-Full Conditions
In a near-memory-full condition, where evictions are not happening fast enough to keep the data set within its BigMemory size limitations, the TSA will put a throttle on operations for a temporary period while it attempts to automatically recover in the background. If unable to recover, the TSA will move into "restricted mode" to prevent out-of-memory errors. The Terracotta Management Console (TMC) uses events to report when the TSA enters restricted mode and allows you to execute additional recovery measures.
Summary of TSA behavior in near-memory-full conditions:
- If usage reaches its critical threshold, T1, then it enters "throttle mode," where writes are slowed while the TSA attempts to evict eligible cache entries in order to bring memory usage within the configured range.
- If usage reaches its halt threshold, T2, then it enters "restricted mode," where writes are blocked, an exception is thrown, and operator intervention is needed to reduce memory usage.
- When usage falls below T1, then the TSA returns to normal operation.
| Throttle mode | Restricted mode | |
|---|---|---|
| Entered when | Used or Reserved usage crosses its critical threshold | Used or Reserved usage crosses its halt threshold |
| Operator event | "TPS seems really low; marking us as being throttled' | "We're in restricted mode; waiting a while and retrying" |
| Data access | Modifications to in-memory data are slowed | Modifications to in-memory data are blocked |
| Allowed operations | All cache operations still allowed | Only gets, removes, and config changes are allowed |
| Actions | Evictions continue automatically in the background | Operator intervention required to make additional evictions |
| State of the data | Evictable data is still present | No more data present in memory that can be evicted by the evictor (all caches are pinned) |
| Recovery | Automatic | From the TMC or programmatically, clear caches and/or remove entries from a data set |
| Back to normal operation | As soon as the background evictions have time to catch up and reduce the data set to within its limitations | After user intervention clears space, the TSA will automatically continue with normal operation |
Restricted Mode Operations
If the TSA is temporarily under restricted mode, any change to the data set which may result in increased resource utilization is not allowed, including all put and replace methods. Restricted mode does allow gets, removes, configuration changes, and other operations.
Recovery
Recovery from throttle mode is automatic, as soon as the background evictions have time to reduce the data set to within its limitations.
If the TSA enters restricted mode, operator events will be logged in the TMC, and user or programmatic intervention is necessary. In the TMC, you can initiate actions to manually reduce the data set. You can also anticipate operator events and use programmatic logic to respond appropriately.
The following actions are recommended for reducing the data set:
- Clear caches (from the TMC or programmatically)
- Remove entries from data sets programmatically
Note: Because eviction in restricted mode is resource-driven, changing TTI/TTL or maximum capacity will not move the TSA out of restricted mode.
To clear caches from the TMC, click the Application Data tab and the Management sub-tab. Each cache will have a clickable option to Clear Cache. Note that caution should be used when considering whether to clear a pinned cache.
Cluster Events
Cluster events report topology changes, performance issues, and errors in operations. These events are logged by both Terracotta server (L2) and client (L1), and can also be viewed in the TMC.
By default, the L2 stores a maximum of 100 events in memory, and this is the number pulled by the TMC. To edit that number, use the Terracotta property l2.operator.events.store. To set the property in the Terracotta configuration file, use:
<tc-properties>
...
<property name="l2.operator.events.store" value="500" />
</tc-properties>
Event Types and Definitions
The following table describes the types of event that can be found in logs or viewed in the TMC.
| Event Category Type |
Level | Cause | Action | Notes |
|---|---|---|---|---|
| ClusterStateEvents old.db |
INFO | Active L2 restarting with data recovered from disk. | ||
| ClusterTopologyEvent config.reloaded |
INFO | Cluster configuration was reloaded. | ||
| DGCMessages dgc.started |
INFO | Periodic DGC, which was explicitly enabled in configuration, has started a cleanup cycle. | If periodic DGC is unneeded, disable to improve overall cluster performance. | Periodic DGC, which is disabled by default, is mostly useful for toolkit, which lacks automatic handling of distributed garbage. |
| DGCMessages dgc.finished |
INFO | Periodic DGC, which was explicitly enabled in configuration, ended a cleanup cycle. | If periodic DGC is unneeded, disable to improve overall cluster performance. | Periodic DGC, which is disabled by default, is mostly useful for toolkit, which lacks automatic handling of distributed garbage. |
| DGCMessages dgc.canceled |
INFO | Periodic DGC, which was explicitly enabled in configuration, has been cancelled due to an interruption (for example, by a failover operation). | If periodic DGC is unneeded, disable to improve overall cluster performance. | Periodic DGC, which is disabled by default, is mostly useful for toolkit, which lacks automatic handling of distributed garbage. |
| DGCMessages inlineDgc.cleanup .started |
INFO | L2 starting up as active with existing data, triggering inline DGC | Only seen as server starts up as active (from recovery) from restartable. | |
| DGCMessages inlineDgc.cleanup .finished |
INFO | Inline DGC operation completed | ||
| DGCMessages inlineDgc.cleanup .canceled |
INFO | Inline DGC operation interrupted. | Investigate any unusual cluster behavior or other events. | Possibly occurs during failover, but other events should indicate real cause. |
| HAMessages node.joined |
INFO | Specified node has joined the cluster. | ||
| HAMessages node.left |
WARN | Specified node has left the cluster. | Check why the node has left (for example: long gc, network issues, or issues with local node resources). | |
| HAMessages clusterNode StateChanged |
INFO | L2 changing state (for example, from initializing to active). | Check to see that state change is expected. | |
| HAMessages handshake.reject |
ERROR | L1 unsuccessfully trying to reconnect to cluster, but has already be expelled. | L1 should go into a rejoin operation or must be restarted manually. | |
| MemoryManager high.memory .usage |
WARN | Heap usage has crossed its configured threshold. | If combined with longgc, could imply need to relieve memory pressure on L1. | The default threshold can be reconfigured through the high.memory.usage tc-property (refer to tc.properties). |
| MemoryManager long.gc |
WARN | A full GC longer than the configured threshold has occurred. | Reduce cache memory footprint in L1. Investigate issues with application logic and garbage creation. | The default threshold is 8 seconds, and can be reconfigured in tc.properties using longgc.threshhold. Occurrence of this event could help diagnose certain failures, such as in healthchecking. |
| ResourceManagement resource.nearcapacity |
WARN | L2 entered throttled mode, which could be a temporary condition (e.g., caused by bulk-loading) or indicate insufficient allocation of memory to L1s | See the section on responses to memory pressure. | After emitting this, L2 can emit resource.capacityrestored (return to normal mode) or resource.fullcapacity (move to restricted mode), based on resource availability. |
| ResourceManagement resource.fullcapacity |
ERROR | L2 entered restricted mode, which could be a temporary condition (e.g., caused by bulk-loading) or indicate insufficient allocation of memory to L1s | See the section on responses to memory pressure. | After emitting this, L2 can emit resource.capacityrestored (return to normal mode), based on resource availability. |
| ResourceManagement resource .capacityrestored |
INFO | L2 returned to normal from throttled or restricted mode. | ||
| SystemSetupEvent time.different |
WARN | System clocks are not aligned. | Synchronize system clocks. | The default tolerance is 30 seconds, and can be reconfigured in tc.properties using time.sync.threshold. Note that overly large tolerance can introduce unpredictable errors and behaviors. |
| ZapEvents zap.received |
CRITICAL | Another L2 is trying to cause the specified one to restart ("zap"). | Investigate a possible "split brain" situation (a mirror L2 behaves as an active) if the specified L2 does not obey the restart order. | A "zap" operation happens only within a mirror group. |
| ZapEvents zap.accepted |
CRITICAL | The specified L2 is accepting the order to restart ("zap" order). | Check state of the target L2 to ensure that it restarts as mirror or manually restart the L2. | A "zap" order is issued only within a mirror group. |
| ZapEvents dirty.db |
WARN | A mirror L2 is trying to join with data in place. | If the mirror does not automatically restart and wipe its data, its data may need to be manually wiped and before it's restarted. | Restarted mirror L2s must wipe their data to resync with the active L2. This is normally an automatic operation that should not require action. |
Live Backup of Distributed In-memory Data
Backups of the entire data set across all stripes (mirror groups) of the Terracotta Server Array can be made using the TMC Backup feature. This feature creates a time-stamped backup of each stripe's data, providing a snapshot of the TSA's in-memory data.
The Backup feature is available when fast restartability is enabled for the TSA (<restartable enabled="true"/> in the tc-config.xml).
Creating a Backup
From the TMC, select the Administration tab and the Backups sub-tab. Click the Make Backup button to perform a backup. The TMC sends a backup request to all stripes in the cluster.
In order to capture a consistent snapshot of the in-memory data, the backup function creates a pause in transactions, allowing any unfinished transactions to complete, and then the backup is written. This allows the backup to be a consistent record of the entries in-memory, as well as search and other indices.
Note that when backing up a cluster, each stripe is backed up independently and at a slightly different time than the other stripes.
When complete, a window appears that confirms the backup was taken and provides the time-stamped file name(s) of the backup.
Backup Directory
Backups are saved to the default directory data-backup, unless otherwise configured in the tc-config.xml. Terracotta automatically creates data-backup in the directory containing the Terracotta server's configuration file (tc-config.xml by default).
You can override the default directory by specifying a different backup directory in the server's configuration file using the <data-backup> property:
<servers>
<server name="Server1">
<data>/opt/terracotta/server1-data</data>
<data-backup>path/to/my/backup/directory</data-backup>
<offheap>
<enabled>true</enabled>
<maxDataSize>2g</maxDataSize>
</offheap>
</server>
<restartable enabled="true"/>
</servers>
Restoring Data from a Backup
If the TSA fails, on restart it automatically restores data from its data directory, recreating the application state. If the current data files are corrupt or missing, or in other situations where an earlier snapshot of data is required, you can restore them from backups:
- Shut down the Terracotta cluster.
- (Optional) Make copies of any existing data files.
- Delete the existing data files from your Terracotta servers.
- Copy the backup data files to the directory from which you deleted the original (existing) data files.
- Restart the Terracotta cluster.
Server and Client Reconnections
A reconnection mechanism restores lost connections between active and mirror Terracotta server instances. See Automatic Server Instance Reconnect for more information.
A Terracotta Server Array handles perceived client disconnection (for example, a network failure, a long client GC, or node failure) based on the configuration of the HealthChecker or Automatic Client Reconnect mechanisms. A disconnected client also attempts to reconnect based on these mechanisms. The client tries to reconnect first to the initial server, then to any other servers set up in its Terracotta configuration. To preserve data integrity, clients resend any transactions for which they have not received server acks.
Changing Cluster Topology in a Live Cluster
Using the TMC, you can change the topology of a live cluster by reloading an edited Terracotta configuration file.
Note the following restrictions:
- Only the removal or addition of <server> blocks in the <servers> or <mirror-group> section of the Terracotta configuration file are allowed.
All servers and clients must load the same configuration file to avoid topology conflicts.
Servers that are part of the same server array but do not share the edited configuration file must have their configuration file edited and reloaded as shown below. Clients that do not load their configuration from the servers must have their configuration files edited to exactly match that of the servers.
Note: Changing the topology of a live cluster will not affect the distribution of data that is already loaded in the TSA. For example, if you added a stripe to a live cluster, the data in the server array would not be redistributed to utilize it. Instead, the new stripe could be used for adding new caches, while the original servers would continue to manage the original data.
Adding a New Server
To add a new server to a Terracotta cluster, follow these steps:
Add a new <server> block to the <servers> or <mirror-group> section in the Terracotta configuration file being used by the cluster. The new <server> block should contain the minimum information required to configure a new server. It should appear similar to the following, with your own values substituted:
<server host="myHost" name="server2" > <data>%(user.home)/terracotta/server2/server-data</data> <logs>%(user.home)/terracotta/server2/server-logs</logs> <tsa-port>9513</tsa-port> </server>Make sure you are connected to the TMC, and that the TMC is connected to the target cluster.
See the TMC documentation for more information on using the TMC.With the target cluster selected in the TMC, click the Administration tab, then choose the Change Topology panel.
Click Reload.
A message appears with the result of the reload operation. A successful operation logs a message similar to the following:2013-03-14 13:25:44,821 INFO - Successfully overridden server topology from file at'/bigmemory-max-4/tc-config.xml'.
Start the new server.
Removing an Existing Server
To remove a server from a Terracotta cluster configuration, follow these steps:
- Shut down the server you want to remove from the cluster.
If you shutting down an active server, first ensure that a backup server is online to enable failover. Delete the <server> block associated with the removed server from the Terracotta configuration file being used by the cluster. Make sure you are connected to the TMC, and that the TMC is connected to the target cluster.
See the TMC documentation for more information on using the TMC.With the target cluster selected in the TMC, click the Administration tab, then choose the Change Topology panel.
Click Reload.
A message appears with the result of the reload operation. A successful operation logs a message similar to the following:2013-03-14 13:25:44,821 INFO - Successfully overridden server topology from file at '/bigmemory-max-4/tc-config.xml'.The TMC will also display the event
Server topology reloaded from file at '/bigmemory-max-4/tc-config.xml'.
Editing the Configuration of an Existing Server
If you edit the configuration of an existing ("live") server and attempt to reload its configuration, the reload operation will fail. However, you can successfully edit an existing server's configuration by following these steps:
- Remove the server by following the steps in Removing an Existing Server. Instead of deleting the server’s <server> block, you can comment it out.
- Edit the server’s <server> block with the changed values.
- Add (or uncomment) the edited <server> block.
- In the TMC's Change Server Topology panel, click Reload. A message appears with the result of the reload operation.
NOTE: To be able to edit the configuration of an existing server, all clients must load their configuration from the Terracotta Server Array. Clients that load configuration from another source will fail to remain connected to the TSA due to a configuration mismatch.
Production Mode
Production mode can be set by setting the Terracotta property in the Terracotta configuration:
<tc-properties>
...
<property name="l2.enable.legacy.production.mode" value="true" />
</tc-properties>
Production mode requires the --force flag to be used with the stop-tc-server script if the target is an active server with no mirror.
Distributed Garbage Collection
There are two types of DGC: periodic and inline. The periodic DGC is configurable and can be run manually (see below). Inline DGC, which is an automatic garbage-collection process intended to maintain the server's memory, runs even if the periodic DGC is disabled.
Note that the inline DGC algorithm operates at intervals optimal to maximizing performance, and so does not necessarily collect distributed garbage immediately.
Running the Periodic DGC
The periodic DGC can be run in any of the following ways:
- run-dgc shell script – Call the run-dgc shell script to trigger DGC externally.
- JMX – Trigger DGC through the server's JMX management interface.
By default, DGC is disabled in the Terracotta configuration file in the <garbage-collection> section. However, even if disabled, it will run automatically under certain circumstances when clearing garbage is necessary but the inline DGC does not run (such as when a crashed server returns to the cluster).
Monitoring and Troubleshooting the DGC
DGC events (both periodic and inline) are reported in a Terracotta server instance's logs. DGC events can also be monitored using the Terracotta Management Console.
If DGC does not seem to be collecting objects at the expected rate, one of the following issues may be the cause:
- Java GC is not able to collect objects fast enough. Client nodes may be under resource pressure, causing GC collection to run behind, which then causes DGC to run behind.
- Certain client nodes continue to hold references to objects that have become garbage on other nodes, thus preventing DGC from being able to collect those objects.
If possible, shut down all Terracotta clients to see if DGC then collects the objects that were expected to be collected.