Commercial Products
Open Source
Terracotta Server Arrays Architecture
Introduction
This document shows you how to add cluster reliability, availability, and scalability to a Terracotta Server Array.
A Terracotta Server Array can vary from a basic two-node tandem to a multi-node array providing configurable scale, high performance, and deep failover coverage.
| This document may refer to a Terracotta server instance as L2, and a Terracotta client (the node running your application) as L1. These are the shorthand references used in Terracotta configuration files. |
Definitions and Functional Characteristics
The major components of a Terracotta installation are the following:
- Cluster – All of the Terracotta server instances and clients that work together to share application state or a data set.
- Terracotta Server Array – The platform, consisting of all of the Terracotta server instances in a single cluster. Clustered data, also called in-memory data, or shared data, is partitioned equally among active Terracotta server instances for management and persistence purposes.
- Terracotta mirror group – A unit in the Terracotta Server Array. Sometimes also called a "stripe," a mirror group is composed of exactly one active Terracotta server instance and at least one "hot standby" Terracotta server instance (simply called a "standby"). The active server instance manages and persists the fraction of shared data allotted to its mirror group, while each standby server in the mirror group replicates (or mirrors) the shared data managed by the active server. Mirror groups add capacity to the cluster. The standby servers are optional but highly recommended for providing failover.
- Terracotta server instance – A single Terracotta server. An active server instance manages Terracotta clients, coordinates shared objects, and persists data. Server instances have no awareness of the clustered applications running on Terracotta clients. A standby (sometimes called "passive") is a live backup server instance which continuously replicates the shared data of an active server instance, instantaneously replacing the active if the active fails. Standby servers add failover coverage within each mirror group.
- Terracotta client – Terracotta clients run on application servers along with the applications being clustered by Terracotta. Clients manage live shared-object graphs.
Another component of the cluster is the embedded database. The Terracotta Server Array uses a licensed database, called BerkeleyDB, to back up all shared (distributed) data. To switch to using Apache Derby as the embedded database, simply add the following property to the Terracotta configuration file’s <tc-properties> block then start or restart the Terracotta Server Array:
You can set additional Apache Derby properties using <property> elements in the <tc-properties> block. For example, to set the property To reset to the default embedded database, remove all Derby-related properties from the Terracotta configuration file and restart the Terracotta Server Array. If you are using Terracotta Server Array 3.5.1 or later, and want to completely remove BerkeleyDB from your environment, delete the file |
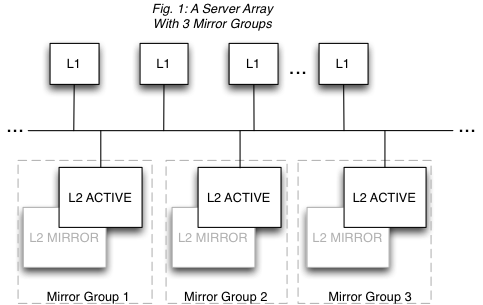
Figure 1 illustrates a Terracotta cluster with three mirror groups. Each mirror group has an active server and a standby, and manages one third of the shared data in the cluster.
A Terracotta cluster has the following functional characteristics:
- Each mirror group automatically elects one active Terracotta server instance. There can never be more than one active server instance per mirror group, but there can be any number of standbys. In Fig. 1, Mirror Group 1 could have two standbys, while Mirror Group 3 could have four standbys. However, a performance overhead may become evident when adding more standby servers due to the load placed on the active server by having to synchronize with each standby.
- Every mirror group in the cluster must have a Terracotta server instance in active mode before the cluster is ready to do work.
- The shared data in the cluster is automatically partitioned and distributed to the mirror groups. The number of partitions equals the number of mirror groups. In Fig. 1, each mirror group has one third of the shared data in the cluster.
- Mirror groups can not provide failover for each other. Failover is provided within each mirror group, not across mirror groups. This is because mirror groups provide scale by managing discrete portions of the shared data in the cluster -- they do not replicate each other. In Fig. 1, if Mirror Group 1 goes down, the cluster must pause (stop work) until Mirror Group 1 is back up with its portion of the shared data intact.
- Active servers are self-coordinating among themselves. No additional configuration is required to coordinate active server instances.
- Only standby server instances can be hot-swapped in an array. In Fig. 1, the L2 PASSIVE (standby) servers can be shut down and replaced with no affect on cluster functions. However, to add or remove an entire mirror group, the cluster must be brought down. Note also that in this case the original Terracotta configuration file is still in effect and no new servers can be added. Replaced standby servers must have the same address (hostname or IP address). If you must swap in a standby with a different configuration, and you have an enterprise edition of Terracotta, see Changing Cluster Topology in a Live Cluster.
Server Array Configuration Tips
To successfully configure a Terracotta Server Array using the Terracotta configuration file, note the following:
- Two or more servers should be defined in the <servers> section of Terracotta configuration file.
- <l2-group-port> is the port used by the Terracotta server to communicate with other Terracotta servers.
The <ha> section, which appears immediately after the last <server> section (or the <mirror-groups> section), should declare the mode as "networked-active-passive":
networked-active-passive 5
The active-passive mode "disk-based-active-passive" is not recommended except for demonstration purposes or where a networked connection is not feasible. See the cluster architecture section in the Terracotta Concept and Architecture Guide for more information on disk-based active-passive mode. * The <networked-active-passive> subsection has a configurable parameter called <election-time> whose value is given in seconds. <election-time> sets the duration for electing an ACTIVE server, often a factor in network latency and server load. The default value is 5 seconds.
| When using networked-active-passive mode, Terracotta server instances must not share data directories. Each server's <data> element should point to a different and preferably local data directory. |
- A reconnection mechanism restores lost connections between active and passive Terracotta server instances. See Automatic Server Instance Reconnect for more information.
- A reconnection mechanism restores lost connections between Terracotta clients and server instances. See Automatic Client Reconnect for more information.
- For data safety, persistence should be set to "permanent-store" for server arrays. "permanent-store" means that application state, or shared in-memory data, is backed up to disk. In case of failure, it is automatically restored. Shared data is removed from disk once it no longer exists in any client's memory.
| All servers and clients should be running the same version of Terracotta and Java. |
For more information on Terracotta configuration files, see:
- Working with Terracotta Configuration Files
- Configuration Guide and Reference (Servers Configuration Section)
Backing Up Persisted Shared Data
Certain versions of Terracotta provide tools to create backups of the Terracotta Server Array disk store. See the Terracotta Operations Center and the Database Backup Utility (backup-data) for more information.
Client Disconnection
Any Terracotta Server Array handles perceived client disconnection (for example a network failure, a long client GC, or node failure) based on the configuration of the HealthChecker or Automatic Client Reconnect mechanisms. A disconnected client also attempts to reconnect based on these mechanisms. The client tries to reconnect first to the initial server, then to any other servers set up in its Terracotta configuration. To preserve data integrity, clients resend any transactions for which they have not received server acks.
For more information on client behavior, see Cluster Structure and Behavior.
Cluster Structure and Behavior
The Terracotta cluster can be configured into a number of different setups to serve both deployment stage and production needs. Note that in multi-setup setups, failover characteristics are affected by HA settings (see Configuring Terracotta Clusters For High Availability).
Terracotta Cluster in Development
Persistence: No | Failover: No | Scale: No
In a development environment, persisting shared data is often unnecessary and even inconvenient. It puts more load on the server, while accumulated data can fill up disks or prevent automatic restarts of servers, requiring manual intervention. Running a single-server Terracotta cluster without persistence is a good solution for creating a more efficient development environment.
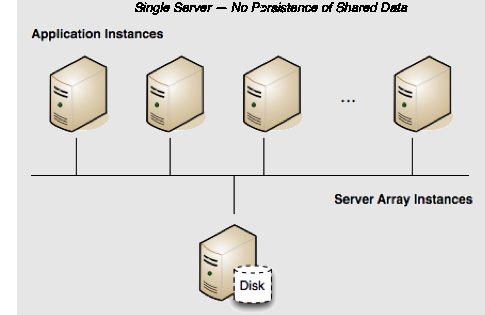
By default, a single Terracotta server is in "temporary-swap-mode", which means it lacks persistence. Its configuration could look like the following:
<?xml version="1.0" encoding="UTF-8" ?>
<tc:tc-config xmlns:tc="http://www.terracotta.org/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.terracotta.org/schema/terracotta-5.xsd">
<servers>
<server name="Server1">
<data>/opt/terracotta/server1-data</data>
<l2-group-port>9530</l2-group-port>
</server>
<servers>
...
</tc:tc-config>
Server Restart
If this server goes down, all application state (all clustered data) in the shared heap is lost. In addition, when the server is up again, all clients must be restarted to rejoin the cluster.
Terracotta Cluster With Reliability
Persistence: Yes | Failover: No | Scale: No
The "unreliable" configuration in Terracotta Cluster in Development may be advantageous in development, but if shared in-memory data must be persisted, the server's configuration must be expanded:
<?xml version="1.0" encoding="UTF-8" ?>
<tc:tc-config xmlns:tc="http://www.terracotta.org/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.terracotta.org/schema/terracotta-5.xsd">
<servers>
<server name="Server1">
<data>/opt/terracotta/server1-data</data>
<l2-group-port>9530</l2-group-port>
<dso>
<!-- The persistence mode is "temporary-swap-only" by default, so it must be changed explicitly. -->
<persistence>
<mode>permanent-store</mode>
</persistence>
</dso>
</server>
</servers>
...
</tc:tc-config>
The value of the <persistence> element's <mode> subelement is "temporary-swap-only" by default. By changing it to "permanent-store", the server now backs up all shared in-memory data to disk.
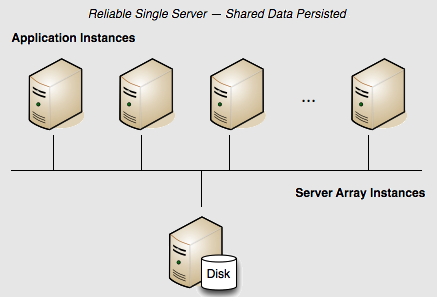
Server Restart
If the server is restarted, application state (all clustered data) in the shared heap is restored.
In addition, previously connected clients are allowed to rejoin the cluster within a window set by the <client-reconnect-window> element:
<?xml version="1.0" encoding="UTF-8" ?>
<tc:tc-config xmlns:tc="http://www.terracotta.org/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.terracotta.org/schema/terracotta-5.xsd">
<servers>
<server name="Server1">
<data>/opt/terracotta/server1-data</data>
<l2-group-port>9530</l2-group-port>
<dso>
<!-- By default the window is 120 seconds. -->
<client-reconnect-window>120</client-reconnect-window>
<!-- The persistence mode is "temporary-swap-only" by default, so it must be changed explicitly. -->
<persistence>
<mode>permanent-store</mode>
</persistence>
</dso>
</server>
</servers>
...
</tc:tc-config>
The <client-reconnect-window> does not have to be explicitly set if the default value is acceptable. However, in a single-server cluster <client-reconnect-window> is in effect only if persistence mode is set to "permanent-store".
Terracotta Server Array with High Availability
Persistence: Yes | Failover: Yes | Scale: No
The example illustrated in Fig. 3 presents a reliable but not highly available cluster. If the server fails, the cluster fails. There is no redundancy to provide failover. Adding a standby server adds availability because the standby failover (see Fig. 4).
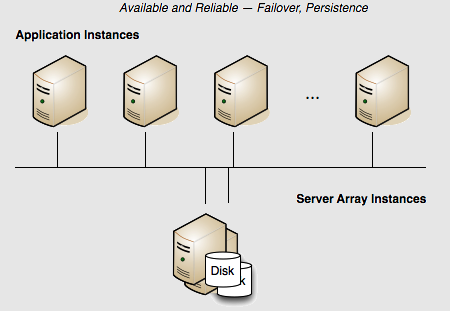
In this array, if the active Terracotta server instance fails then the standby instantly takes over and the cluster continues functioning. No data is lost.
The following Terracotta configuration file demonstrates how to configure this two-server array:
<?xml version="1.0" encoding="UTF-8" ?>
<tc:tc-config xmlns:tc="http://www.terracotta.org/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.terracotta.org/schema/terracotta-5.xsd">
<servers>
<server name="Server1">
<data>/opt/terracotta/server1-data</data>
<l2-group-port>9530</l2-group-port>
<dso>
<persistence>
<mode>permanent-store</mode>
</persistence>
</dso>
</server>
<server name="Server2">
<data>/opt/terracotta/server2-data</data>
<l2-group-port>9530</l2-group-port>
<dso>
<persistence>
<mode>permanent-store</mode>
</persistence>
</dso>
</server>
<ha>
<mode>networked-active-passive</mode>
<networked-active-passive>
<election-time>5</election-time>
</networked-active-passive>
</ha>
</servers>
...
</tc:tc-config>
The recommended <mode> in the <ha> section is "networked-active-passive" because it allows the active and passive servers to synchronize directly, without relying on a disk.
You can add more standby servers to this configuration by adding more <server> sections. However, a performance overhead may become evident when adding more standby servers due to the load placed on the active server by having to synchronize with each standby.
Starting the Servers
How server instances behave at startup depends on when in the life of the cluster they are started.
In a single-server configuration, when the server is started it performs a startup routine and then is ready to run the cluster (ACTIVE status). If multiple server instances are started at the same time, one is elected the active server (ACTIVE-COORDINATOR status) while the others serve as standbys (PASSIVE-STANDBY status). The election is recorded in the servers’ logs.
If a server instance is started while an active server instance is present, it syncs up state from the active server instance before becoming a standby. The active and passive servers must always be synchronized, allowing the passive to mirror the state of the active. The standby server goes through the following states:
- PASSIVE-UNINITIALIZED – The standby is beginning its startup sequence and is not ready to perform failover should the active fail or be shut down. The server’s status light in the Terracotta Developer Console switches from red to yellow.
- INITIALIZING – The standby is synchronizing state with the active and is not ready to perform failover should the active fail or be shut down. The server’s status light in the Terracotta Developer Console switches from yellow to orange.
- PASSIVE-STANDBY – The standby is synchronized and is ready to perform failover should the active server fail or be shut down. The server’s status light in the Terracotta Developer Console switches from orange to cyan.
The active server instance carries the load of sending state to the standby during the synchronization process. The time taken to synchronize is dependent on the amount of clustered data and on the current load on the cluster. The active server instance and standbys should be run on similarly configured machines for better throughput, and should be started together to avoid unnecessary sync ups.
Failover
If the active server instance fails and two or more standby server instances are available, an election determines the new active. Successful failover to a new active takes place only if at least one standby server is fully synchronized with the failed active server; successful client failover (migration to the new active) can happen only if the server failover is successful. Shutting down the active server before a fully-synchronized standby is available can result in a cluster-wide failure.
| Standbys can be hot swapped if the replacement matches the original standby’s <server> block in the Terracotta configuration. For example, the new standby should use the same host name or IP address configured for the original standby. If you must swap in a standby with a different configuration, and you have an enterprise edition of Terracotta, see Changing Cluster Topology in a Live Cluster |
Terracotta server instances acting as standbys can run either in persistent mode or non-persistent mode. If an active server instance running in persistent mode goes down, and a standby takes over, the crashed server’s data directory must be cleared before it can be restarted and allowed to rejoin the cluster. Removing the data is necessary because the cluster state could have changed since the crash. During startup, the restarted server’s new state is synchronized from the new active server instance. A crashed standby running in persistent mode, however, automatically recovers by wiping its own database.
|
Under certain circumstances, standbys may fail to automatically clear their data directory and fail to restart, generating errors. In this case, the data directory must be manually cleared.
Even if the standby’s data is cleared, a copy of it is saved. By default, the number of copies is unlimited. Over time, and with frequent restarts, these copies may consume a substantial amount of disk space if the amount of shared data is large. You can manually delete these files, which are saved in the server’s data directory under where <myValue> is an integer. To prevent any backups from being saved, add the following element to the Terracotta configuration file’s <tc-properties> block: |
If both servers are down, and clustered data is persisted, the last server to be active should be started first to avoid errors and data loss. Check the server logs to determine which server was last active. (In setups where data is not persisted, meaning that persistence mode is set to "temporary-swap-only", then no data is saved and either server can be started first.)
A Safe Failover Procedure
To safely migrate clients to a standby server without stopping the cluster, follow these steps:
- If it is not already running, start the standby server using the start-tc-server script. The standby server must already be configured in the Terracotta configuration file.
- Ensure that the standby server is ready for failover (PASSIVE-STANDBY status).
Shut down the active server using the stop-tc-server script.
NOTE: If the script detects that the passive server in STANDBY state isn't reachable, it issues a warning and fails to shut down the active server. If failover is not a concern, you can override this behavior with the
--forceflag.Clients should connect to the new active server.
Restart any clients that fail to reconnect to the new active server within the configured reconnection window.
- If running with persistence, delete the database of the previously active server before restarting it. The previously active server can now rejoin the cluster as a standby server.
A Safe Cluster Shutdown Procedure
For a cluster with persistence, a safe cluster shutdown should follow these steps:
- Shut down the standby server using the stop-tc-server script.
- Shut down the clients. The Terracotta client will shut down when you shut down your application.
- Shut down the active server using the stop-tc-server script.
To restart the cluster, first start the server that was last active. If clustered data is not persisted, either server could be started first as no database conflicts can take place.
Split Brain Scenario
In a Terracotta cluster, "split brain" refers to a scenario where two servers assume the role of active server (ACTIVE-COORDINATOR status). This can occur during a network problem that disconnects the active and standby servers, causing the standby to both become an active server and open a reconnection window for clients (<client-reconnect-window>).
If the connection between the two servers is never restored, then two independent clusters are in operation. This is not a split-brain situation. However, if the connection is restored, one of the following scenarios results:
- No clients connect to the new active server – The original active server "zaps" the new active server, causing it to restart, wipe its database, and synchronize again as a standby.
- A minority of clients connect to the new active server – The original active server starts a reconnect timeout (based on HA settings; see Configuring Terracotta Clusters For High Availability) for the clients that it loses, while zapping the new active server. The new active restarts, wipes its database, and synchronizes again as a standby. Clients that defected to the new active attempt to reconnect to the original active, but if they do not succeed within the parameters set by that server, they must be restarted.
- A majority of clients connects to the new active server – The new active server "zaps" the original active server. The original active restarts, wipes its database, and synchronizes again as a standby. Clients that do not connect to the new active within its configured reconnection window must be restarted.
- An equal number of clients connect to the new active server – In this unlikely event, exactly one half of the original active server’s clients connect to the new active server. The servers must now attempt to determine which of them holds the latest transactions (or has the freshest data). The winner zaps the loser, and clients behave as noted above, depending on which server remains active. Manual shutdown of one of the servers may become necessary if a timely resolution does not occur.
The cluster can solve almost all split-brain occurrences without loss or corruption of shared data. However, it is highly recommended that you confirm the integrity of shared data after such an occurrence.
Scaling the Terracotta Server Array
Persistence: Yes | Failover: Yes | Scale: Yes
For capacity requirements that exceed the capabilities of a two-server active-passive setup, expand the Terracotta cluster using a mirror-groups configuration. Mirror groups are available with an enterprise version of Terracotta software. Using mirror groups with multiple coordinated active Terracotta server instances adds scalability to the Terracotta Server Array.
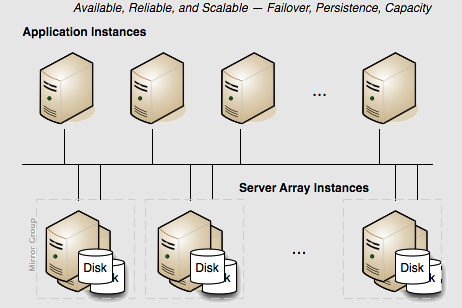
Mirror groups are specified in the <servers> section of the Terracotta configuration file. Mirror groups work by assigning group memberships to Terracotta server instances. The following snippet from a Terracotta configuration file shows a mirror-group configuration with four servers:
...
<servers>
<server name="server1">
...
</server>
<server name="server2">
...
</server>
<server name="server3">
...
</server>
<server name="server4">
...
</server>
<mirror-groups>
<mirror-group group-name="groupA">
<members>
<member>server1</member>
<member>server2</member>
</members>
</mirror-group>
<mirror-group group-name="groupB">
<members>
<member>server3</member>
<member>server4</member>
</members>
</mirror-group>
</mirror-groups>
<ha>
<mode>networked-active-passive</mode>
<networked-active-passive>
<election-time>5</election-time>
</networked-active-passive>
</ha>
</servers>
...
In this example, the cluster is configured to have two active servers, each with its own standby. If server1 is elected active in groupA, server2 becomes its standby. If server3 is elected active in groupB, server4 becomes its standby. server1 and server2 automatically coordinate their work managing Terracotta clients and shared data across the cluster.
In a Terracotta cluster designed for multiple active Terracotta server instances, the server instances in each mirror group participate in an election to choose the active. Once every mirror group has elected an active server instance, all the active server instances in the cluster begin cooperatively managing the cluster. The rest of the server instances become standbys for the active server instance in their mirror group. If the active in a mirror group fails, a new election takes place to determine that mirror group's new active. Clients continue work without regard to the failure.
In a Terracotta cluster with mirror groups, each group, or "stripe," behaves in a similar way to an active-passive setup (see Terracotta Server Array with High Availability). For example, when a server instance is started in a stripe while an active server instance is present, it synchronizes state from the active server instance before becoming a standby. A standby cannot become an active server instance during a failure until it is fully synchronized. If an active server instance running in persistent mode goes down, and a standby takes over, the data directory must be cleared before bringing back the crashed server.
| Standbys can be hot swapped if the replacement matches the original standby’s <server> block in the Terracotta configuration. For example, the new standby should use the same host name or IP address configured for the original standby. If you must swap in a standby with a different configuration, and you have an enterprise edition of Terracotta, see Changing Cluster Topology in a Live Cluster. |
Stripe and Cluster Failure
If the active server in a mirror group fails or is taken down, the cluster stops until a standby takes over and becomes active (ACTIVE-COORDINATOR status).
However, the cluster cannot survive the loss of an entire stripe. If an entire stripe fails and no server in the failed mirror-group becomes active within the allowed window (based on HA settings; see Configuring Terracotta Clusters For High Availability), the entire cluster must be restarted.
High Availability Per Mirror Group
High-availability configuration can be set per mirror group. The following snippet from a Terracotta configuration file shows a mirror-group configured with its own high-availability section:
...
<servers>
<server name="server1">
...
</server>
<server name="server2">
...
</server>
<server name="server3">
...
</server>
<server name="server4">
...
</server>
<mirror-groups>
<mirror-group group-name="groupA">
<members>
<member>server1</member>
<member>server2</member>
</members>
<ha>
<mode>networked-active-passive</mode>
<networked-active-passive>
<election-time>10</election-time>
</networked-active-passive>
</ha>
</mirror-group>
<mirror-group group-name="groupB">
<members>
<member>server3</member>
<member>server4</member>
</members>
</mirror-group>
</mirror-groups>
<ha>
<mode>networked-active-passive</mode>
<networked-active-passive>
<election-time>5</election-time>
</networked-active-passive>
</ha>
</servers>
...
In this example, the servers in groupA can take up to 10 seconds to elect an active server. The servers in groupB take their election time from the <ha> section outside the <mirror-groups> block, which is in force for all mirror groups that do not have their own <ha> section.
See the mirror-groups section in the Configuration Guide and Reference for more information on mirror-groups configuration elements.
About Distributed Garbage Collection
Every Terracotta server instance runs a garbage collection algorithm to determine which clustered objects can be safely removed both from the memory and the disk store of the server instance. This garbage collection process, known as the Distributed Garbage Collector (DGC), is analogous to the JVM garbage collector but works only on clustered object data in the server instance.
The DGC is not a distributed process; it operates only on the distributed object data in the Terracotta server instance in which it lives. In essence, the DGC process walks all of the clustered object graphs in a single Terracotta server instance to determine what is currently not garbage. Every object that is garbage is removed from the server instance's memory and from persistent storage (the object store on disk). If garbage objects were not removed from the object store, eventually the disk attached to a Terracotta server instance would fill up.
A clustered object is considered garbage when it is treated as garbage by Java GC. Typically, this happens when an object is not referenced by any other distributed object AND is not resident in any client's heap. Objects that satisfy only one of these conditions are safe from a DGC collection.
In distributed Ehcache, objects that exist in any cache are never collecte by DGC. Objects that are removed from a distributed cache are eligible for collection.
Types of DGC
There are two types of DGC: Periodic and inline. The periodic DGC is configurable and can be run manually (see below). Inline DGC, which is an automatic garbage-collection process intended to maintain the server's memory, runs even if the periodic DGC is disabled.
Note that the inline DGC algorithm operates at intervals optimal to maximizing performance, and so does not necessarily collect distributed garbage immediately.
Running the Periodic DGC
The periodic DGC can be run in any of the following ways:
- Automatically – By default DGC is enabled in the Terracotta configuration file in the
<garbage-collection>section. However, even if disabled, it will run automatically under certain circumstances when clearing garbage is necessary but the inline DGC does not run (such as when a crashed returns to the cluster). - Terracotta Administrator Console – Click the Run DGC button to trigger DGC.
- run-dgc shell script – Call the run-dgc shell script to trigger DGC externally.
- JMX – Trigger DGC through the server's JMX management interface.
Monitoring and Troubleshooting the DGC
DGC events (both periodic and inline) are reported in a Terracotta server instance's logs. DGC can also be monitored using the Terracotta Administrator Console and its various stages. See the Terracotta Administrator Console for more information.
If DGC does not seem to be collecting objects at the expected rate, one of the following issues may be the cause:
- Java GC is not able to collect objects fast enough. Client nodes may be under resource pressure, causing GC collection to run behind, which then causes DGC to run behind.
- Certain client nodes continue to hold references to objects that have become garbage on other nodes, thus preventing DGC from being able to collect those objects.
If possible, shut down all Terracotta clients to see if DGC then collects the objects that were expected to be collected.